 Buy Crypto
Buy Crypto- Markets
 Futures
Futures- Spot
- Copy Trade
- Earn
- More
Claude's Journey to Foolishness in Diagrams: The Cost of Thriftiness, or How API Bill Increased 100-Fold
A few days ago, Stella Laurenzo, Head of AI at AMD, posted an issue titled "Claude Code Unusable for Complex Engineering Tasks" in the Claude Code official repository. This was not a user's emotional complaint but a quantitative analysis based on 6,800 sessions. It brought to the forefront the AI community's most unwilling-to-face issue, with one set of numbers particularly standing out: a cost-saving configuration tweak by Anthropic skyrocketed this team's API monthly bill from $345 to $42,121.
Laurenzo's team tracked 235,000 tool invocations, 18,000 prompts, and documented the systemic performance degradation of Claude Code since February 2026. This report was later covered by The Register, sparking a two-week-long storm of public opinion in the developer community.
Boris Cherny, Head of the Anthropic Claude Code team, provided an explanation on Hacker News. On February 9, with the release of Opus 4.6, a "self-thinking" mechanism was enabled by default, where the model autonomously decides the thought duration. On March 3, Anthropic then lowered the default thinking effort to 85. The official explanation was "the optimal balance point between intelligence, latency, and cost." The actual impact of these two adjustments is evident from the data.
Thought Depth Plummets by Three Quarters
According to Stella Laurenzo's GitHub Issue data, Claude Code's average thought depth experienced a three-stage collapse over two months: from a high of 2,200 characters at the end of January to 720 characters by the end of February, a 67% drop. By March, it further shrunk to 560 characters, a 75% decrease from the peak.
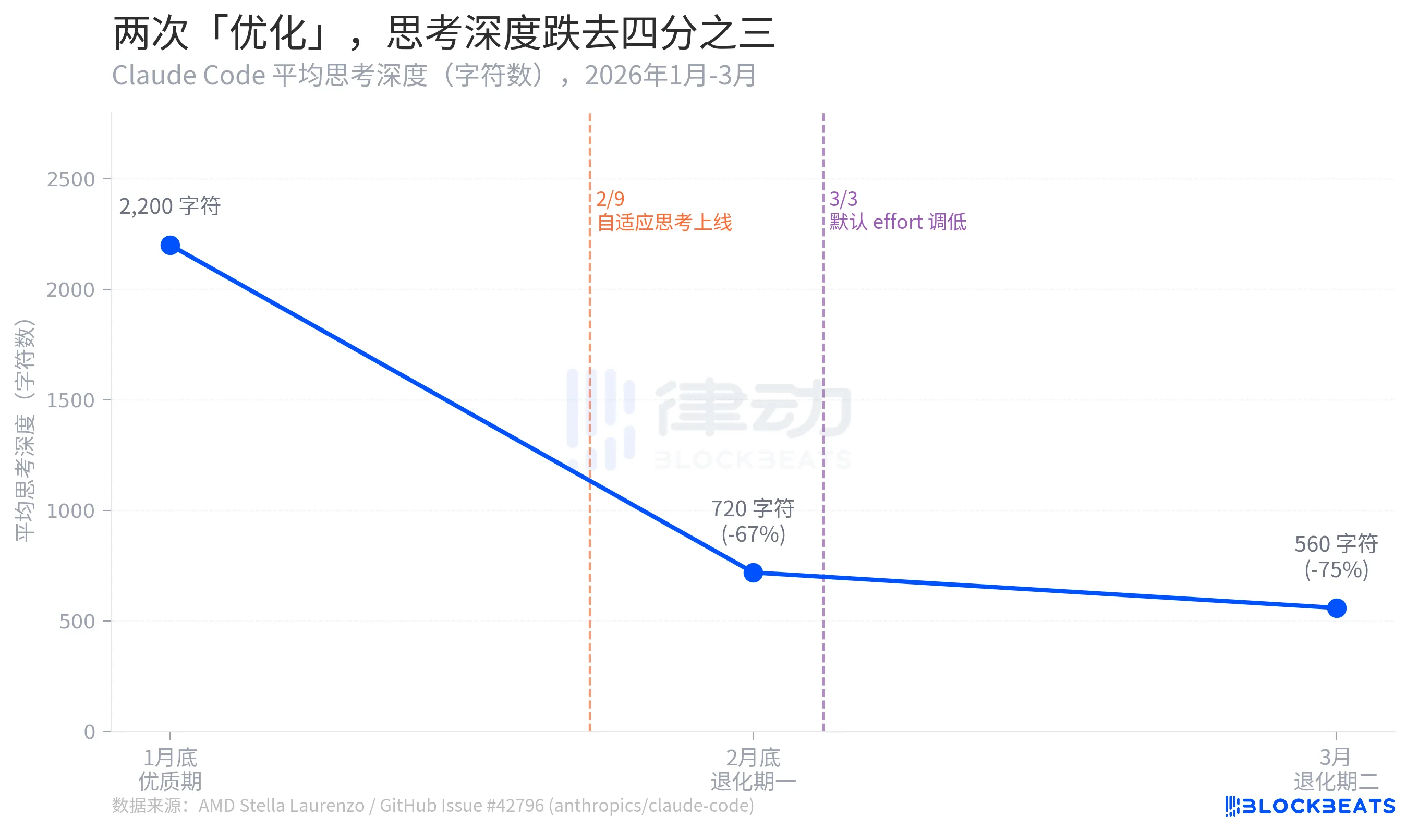
Thought depth here is a proxy metric reflecting how much "internal deliberation" the model is willing to engage in before providing an answer. The difference between 2,200 and 560 characters is roughly equivalent to degrading from "drafting before responding" to "thinking for two seconds in your head before speaking."
Laurenzo also pointed out that the "Thought Content Redaction" feature (redact-thinking-2026-02-12) launched in early March coincidentally masked the model's thought process during this period, making the shrinkage less perceptible to users. Boris Cherny insists this was merely a UI change and did not affect the underlying reasoning. Both claims are technically valid, but from a user's perspective, the effect is indistinguishable.
Boris Cherny later acknowledged that even manually setting the effort back to maximum, the self-thought mechanism may still allocate insufficient reasoning in some rounds, leading to hallucinatory content. "Restoring maximum effort" is not a complete solution; it merely turns the knob back closer to its original position rather than restoring it to its original determinism.
From "Research-Oriented Programmer" to "Blind Edit Programmer"
A detail in Stella Laurenzo's report is more explicit than thinking depth: how many relevant files the model actively reads before making changes to the code.
According to GitHub Issue data, during the prime period, the average read-to-edit ratio is 6.6. Before making a code change, the model, on average, reads 6.6 files to understand the context. During the decay period, this number drops to 2.0, a 70% decrease. More critically, about one-third of code edits occur without the model reading the target file, diving straight in.
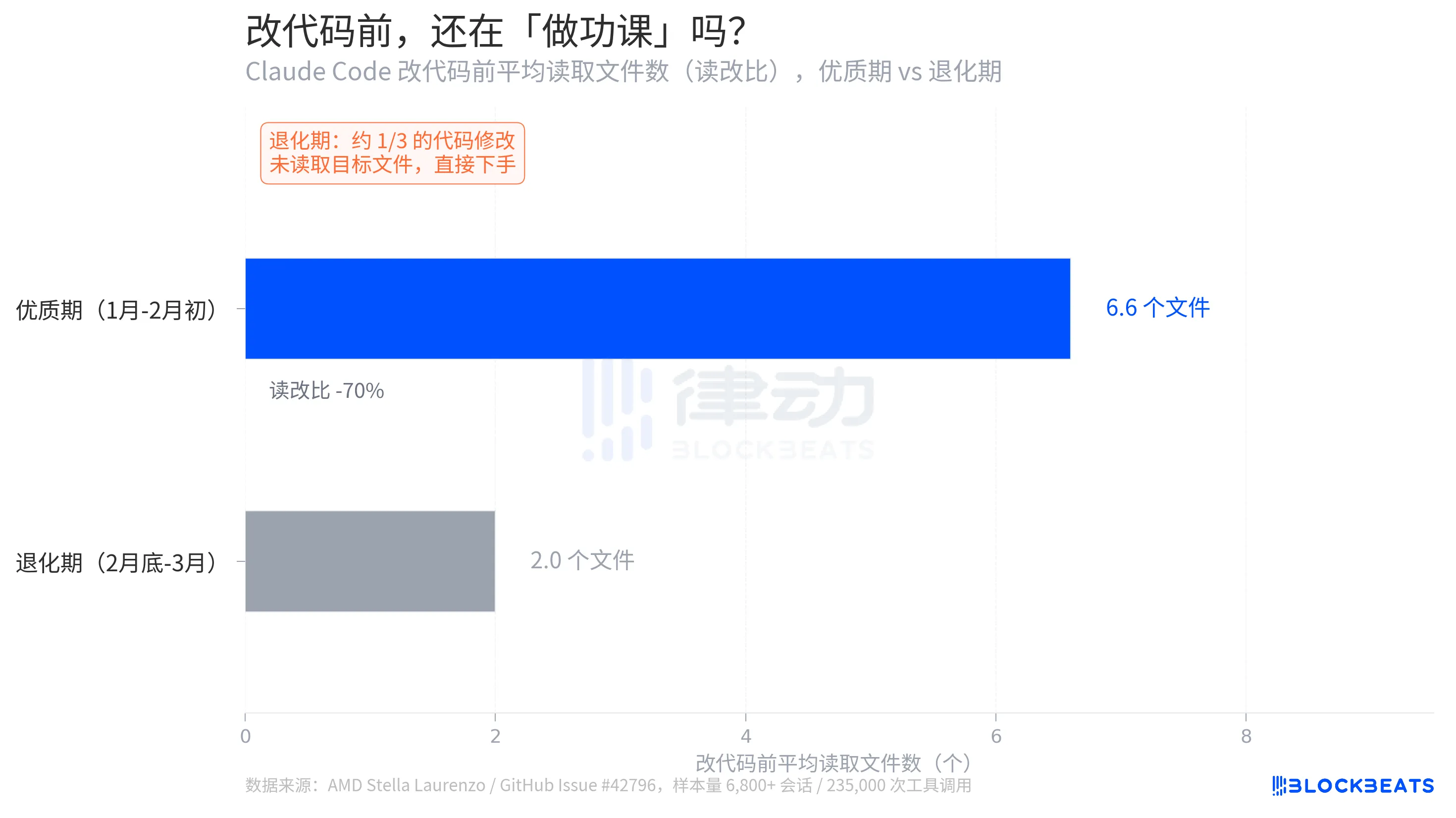
Laurenzo refers to this as "blind edits." In engineering terms, this is akin to a programmer writing code without looking at function signatures or knowing variable types. "Every senior engineer on my team has had similar first-hand experiences," she wrote in her report. "Claude can no longer be trusted to carry out complex engineering tasks."
The drop from a 6.6 read-to-edit ratio to 2.0 is not merely a behavioral metric shift; it signifies a collapse in task success rates. The complexity of modern code repositories dictates that any modification involves dependencies across multiple files. Skipping context exploration and directly making changes doesn't lead to merely "incorrect answers" but rather to "seemingly correct changes that trigger new errors downstream. The cost of debugging such errors far exceeds that of a single failed explicit answer.
The Paradox of "Saving Money"
One of the most counterintuitive sets of numbers in the entire incident comes from the same GitHub Issue data: Stella Laurenzo's team saw the monthly invocation costs of Claude Code API plummet from $345 in February 2026 to a whopping $42,121 in March, a 122-fold increase.
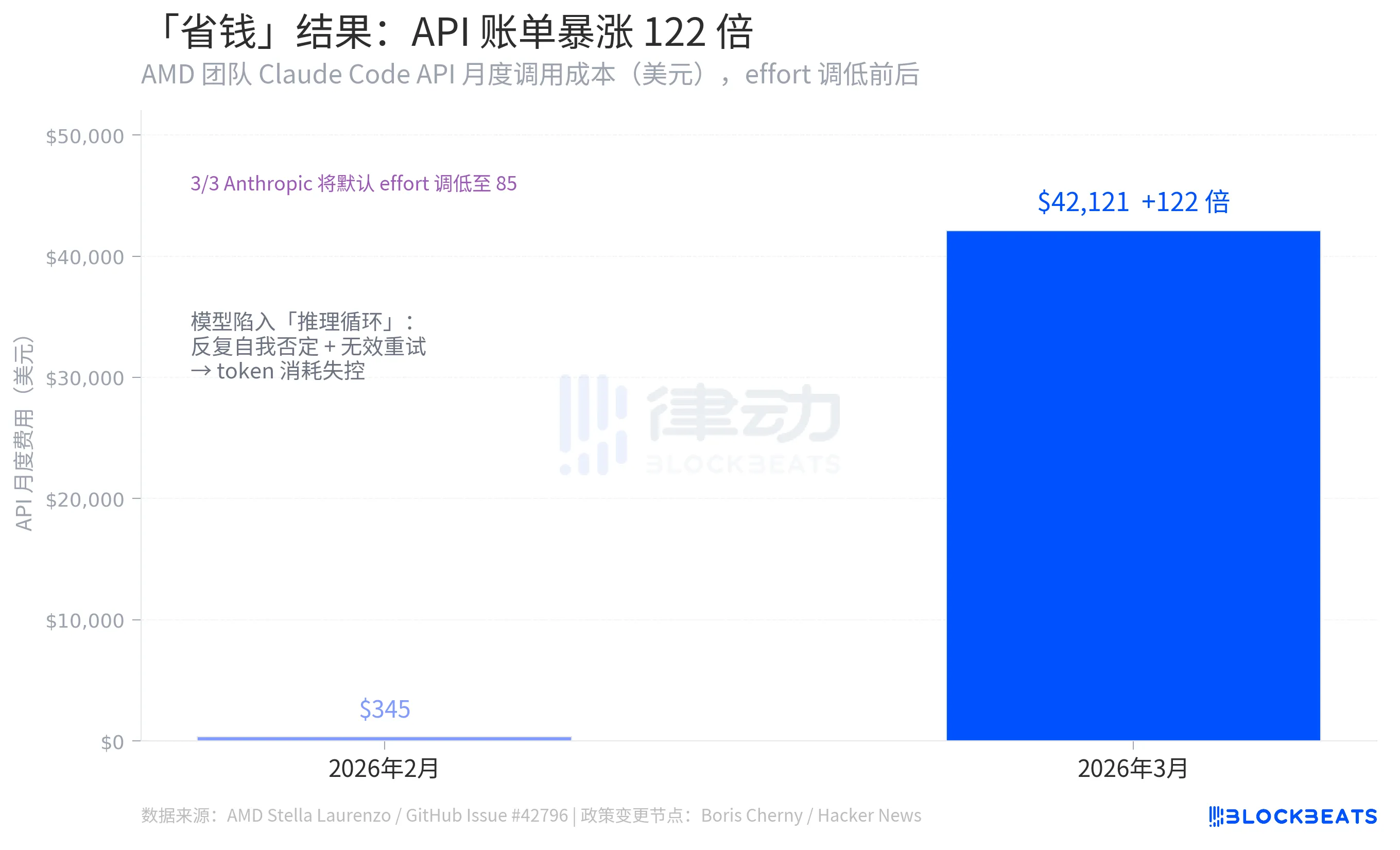
The logic behind Anthropics' effort reduction was to lower the token consumption per call, thus reducing costs. However, the outcome was the opposite. The reason behind this was the emergence of numerous "reasoning loops" after the model's decay, leading to repeated self-negation within a single reply, constant restarts, and a token consumption far exceeding the saved amount. According to Stella Laurenzo's data, the rate of users voluntarily aborting tasks increased by 12 times during the same period, requiring developers' continuous intervention, correction, and resubmission.
The underlying logic is a systemic error. Slashing computational power on a complex task does not simply proportionally reduce costs. Once below a certain threshold of thought, the model starts to veer off track, and the overall cost ends up escalating. Lowering effort saved money on simple queries, but on coding tasks, it blew up the bill.
The "Dumbing Down" Thing, GPT-4 Did It Three Years Ago
In July 2023, a research team from Stanford University and the University of California, Berkeley, published a paper on arXiv titled "How is ChatGPT's behavior changing over time?", documenting the same phenomenon happening on GPT-4.
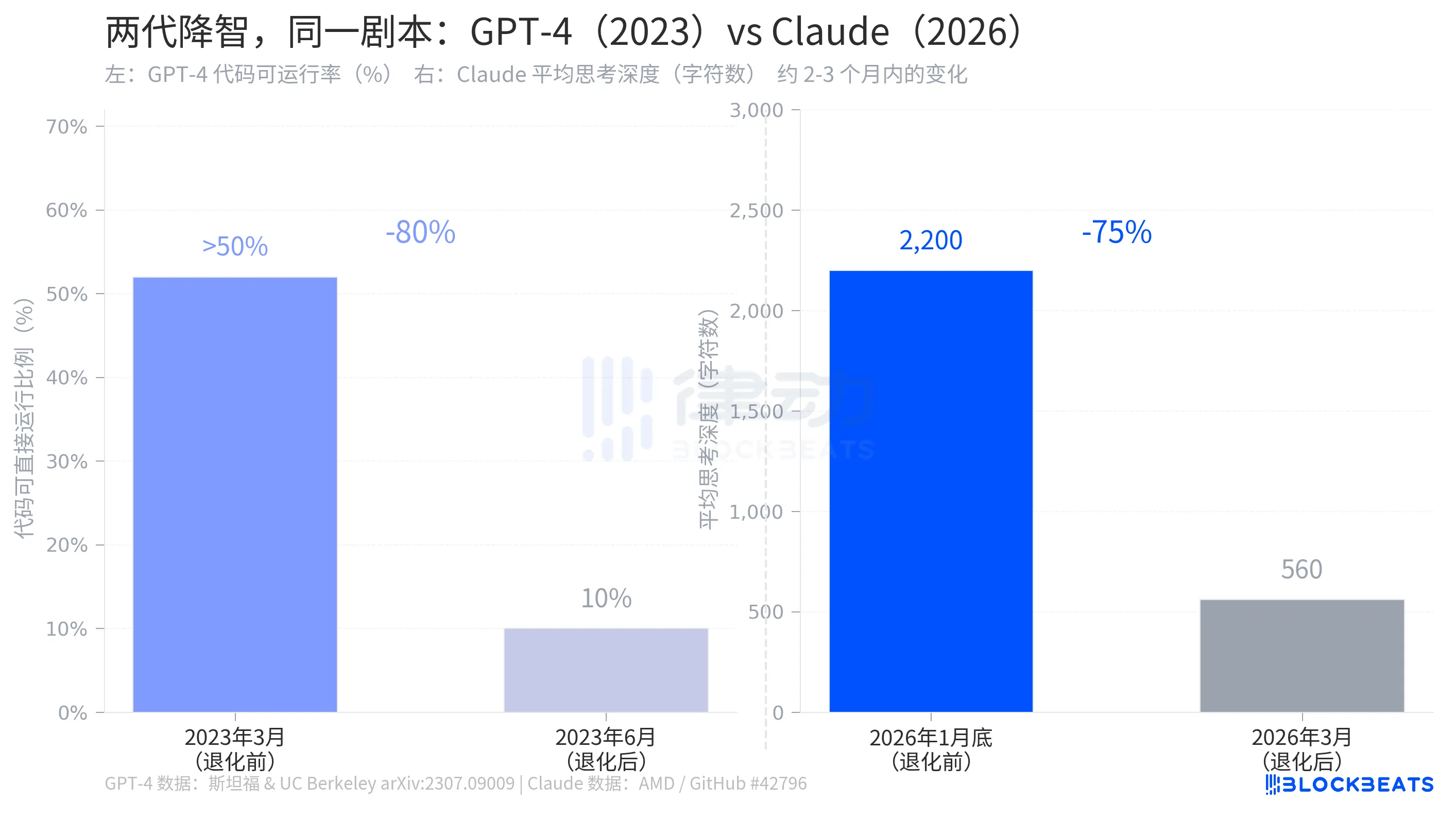
According to the research data, in March 2023, GPT-4 had generated code where over 50% was directly runnable. By June, this proportion had dropped to 10%, an 80% decrease over three months. During the same period, the prime number identification accuracy plummeted from 97.6% to 2.4%. OpenAI's response was highly similar to Anthropic's: there had been optimizations in the background, part of normal iteration.
The structure of the two stories is almost identical: an AI company quietly adjusted parameters affecting the model's capabilities in the background, users noticed, the company acknowledged the adjustment, but explained it as "more reasonable resource allocation." GPT-4's degradation occurred in 2023, Claude's degradation happened in 2026, three years apart, but the script is the same.
This is not a specific company's peculiar mistake. The economic logic of AI subscription models determines that when reasoning costs exceed the pricing that can be covered, manufacturers face the same pressure. Lowering the default thought intensity is currently the easiest knob to turn between cost and performance. What users perceive is the model "getting dumber." What the manufacturer saves on the books is the marginal token cost per call.
Boris Cherny has provided a technical solution where users can manually restore the thought intensity to the highest level through the /effort high command or by modifying the configuration file. This solution is technically feasible, but it also means that "maximum performance" is no longer the default setting.
From $345 to $42,121, what was spent was not just the budget but also an assumption: the default configuration changes made by the manufacturer were intended to improve user experience.
You may also like

TAO is Elon Musk, who invested in OpenAI, and Subnet is Sam Altman

The era of "mass coin distribution" on public chains comes to an end

Soaring 50 times, with an FDV exceeding 10 billion USD, why RaveDAO?

1 billion DOTs were minted out of thin air, but the hacker only made 230,000 dollars

After the blockade of the Strait of Hormuz, when will the war end?

Before using Musk's "Western WeChat" X Chat, you need to understand these three questions
The X Chat will be available for download on the App Store this Friday. The media has already covered the feature list, including self-destructing messages, screenshot prevention, 481-person group chats, Grok integration, and registration without a phone number, positioning it as the "Western WeChat." However, there are three questions that have hardly been addressed in any reports.
There is a sentence on X's official help page that is still hanging there: "If malicious insiders or X itself cause encrypted conversations to be exposed through legal processes, both the sender and receiver will be completely unaware."
No. The difference lies in where the keys are stored.
In Signal's end-to-end encryption, the keys never leave your device. X, the court, or any external party does not hold your keys. Signal's servers have nothing to decrypt your messages; even if they were subpoenaed, they could only provide registration timestamps and last connection times, as evidenced by past subpoena records.
X Chat uses the Juicebox protocol. This solution divides the key into three parts, each stored on three servers operated by X. When recovering the key with a PIN code, the system retrieves these three shards from X's servers and recombines them. No matter how complex the PIN code is, X is the actual custodian of the key, not the user.
This is the technical background of the "help page sentence": because the key is on X's servers, X has the ability to respond to legal processes without the user's knowledge. Signal does not have this capability, not because of policy, but because it simply does not have the key.
The following illustration compares the security mechanisms of Signal, WhatsApp, Telegram, and X Chat along six dimensions. X Chat is the only one of the four where the platform holds the key and the only one without Forward Secrecy.
The significance of Forward Secrecy is that even if a key is compromised at a certain point in time, historical messages cannot be decrypted because each message has a unique key. Signal's Double Ratchet protocol automatically updates the key after each message, a mechanism lacking in X Chat.
After analyzing the X Chat architecture in June 2025, Johns Hopkins University cryptology professor Matthew Green commented, "If we judge XChat as an end-to-end encryption scheme, this seems like a pretty game-over type of vulnerability." He later added, "I would not trust this any more than I trust current unencrypted DMs."
From a September 2025 TechCrunch report to being live in April 2026, this architecture saw no changes.
In a February 9, 2026 tweet, Musk pledged to undergo rigorous security tests of X Chat before its launch on X Chat and to open source all the code.
As of the April 17 launch date, no independent third-party audit has been completed, there is no official code repository on GitHub, the App Store's privacy label reveals X Chat collects five or more categories of data including location, contact info, and search history, directly contradicting the marketing claim of "No Ads, No Trackers."
Not continuous monitoring, but a clear access point.
For every message on X Chat, users can long-press and select "Ask Grok." When this button is clicked, the message is delivered to Grok in plaintext, transitioning from encrypted to unencrypted at this stage.
This design is not a vulnerability but a feature. However, X Chat's privacy policy does not state whether this plaintext data will be used for Grok's model training or if Grok will store this conversation content. By actively clicking "Ask Grok," users are voluntarily removing the encryption protection of that message.
There is also a structural issue: How quickly will this button shift from an "optional feature" to a "default habit"? The higher the quality of Grok's replies, the more frequently users will rely on it, leading to an increase in the proportion of messages flowing out of encryption protection. The actual encryption strength of X Chat, in the long run, depends not only on the design of the Juicebox protocol but also on the frequency of user clicks on "Ask Grok."
X Chat's initial release only supports iOS, with the Android version simply stating "coming soon" without a timeline.
In the global smartphone market, Android holds about 73%, while iOS holds about 27% (IDC/Statista, 2025). Of WhatsApp's 3.14 billion monthly active users, 73% are on Android (according to Demand Sage). In India, WhatsApp covers 854 million users, with over 95% Android penetration. In Brazil, there are 148 million users, with 81% on Android, and in Indonesia, there are 112 million users, with 87% on Android.
WhatsApp's dominance in the global communication market is built on Android. Signal, with a monthly active user base of around 85 million, also relies mainly on privacy-conscious users in Android-dominant countries.
X Chat circumvented this battlefield, with two possible interpretations. One is technical debt; X Chat is built with Rust, and achieving cross-platform support is not easy, so prioritizing iOS may be an engineering constraint. The other is a strategic choice; with iOS holding a market share of nearly 55% in the U.S., X's core user base being in the U.S., prioritizing iOS means focusing on their core user base rather than engaging in direct competition with Android-dominated emerging markets and WhatsApp.
These two interpretations are not mutually exclusive, leading to the same result: X Chat's debut saw it willingly forfeit 73% of the global smartphone user base.
This matter has been described by some: X Chat, along with X Money and Grok, forms a trifecta creating a closed-loop data system parallel to the existing infrastructure, similar in concept to the WeChat ecosystem. This assessment is not new, but with X Chat's launch, it's worth revisiting the schematic.
X Chat generates communication metadata, including information on who is talking to whom, for how long, and how frequently. This data flows into X's identity system. Part of the message content goes through the Ask Grok feature and enters Grok's processing chain. Financial transactions are handled by X Money: external public testing was completed in March, opening to the public in April, enabling fiat peer-to-peer transfers via Visa Direct. A senior Fireblocks executive confirmed plans for cryptocurrency payments to go live by the end of the year, holding money transmitter licenses in over 40 U.S. states currently.
Every WeChat feature operates within China's regulatory framework. Musk's system operates within Western regulatory frameworks, but he also serves as the head of the Department of Government Efficiency (DOGE). This is not a WeChat replica; it is a reenactment of the same logic under different political conditions.
The difference is that WeChat has never explicitly claimed to be "end-to-end encrypted" on its main interface, whereas X Chat does. "End-to-end encryption" in user perception means that no one, not even the platform, can see your messages. X Chat's architectural design does not meet this user expectation, but it uses this term.
X Chat consolidates the three data lines of "who this person is, who they are talking to, and where their money comes from and goes to" in one company's hands.
The help page sentence has never been just technical instructions.
Parse Noise's newly launched Beta version, how to "on-chain" this heat?

Is Lobster a Thing of the Past? Unpacking the Hermes Agent Tools that Supercharge Your Throughput to 100x

Declare War on AI? The Doomsday Narrative Behind Ultraman's Residence in Flames
Crypto VCs Are Dead? The Market Extinction Cycle Has Begun

Edge Land Regress: A Rehash Around Maritime Power, Energy, and the Dollar
Arthur Hayes Latest Interview: How Should Retail Investors Navigate the Iran Conflict?
Just now, Sam Altman was attacked again, this time by gunfire

Straits Blockade, Stablecoin Recap | Rewire News Morning Edition

From High Expectations to Controversial Turnaround, Genius Airdrop Triggers Community Backlash
The Xiaomi electric vehicle factory in Beijing's Daxing district has become the new Jerusalem for the American elite

Lean Harness, Fat Skill: The Real Source of 100x AI Productivity

Ultraman is not afraid of his mansion being attacked; he has a fortress.
TAO is Elon Musk, who invested in OpenAI, and Subnet is Sam Altman
The era of "mass coin distribution" on public chains comes to an end
Soaring 50 times, with an FDV exceeding 10 billion USD, why RaveDAO?
1 billion DOTs were minted out of thin air, but the hacker only made 230,000 dollars
After the blockade of the Strait of Hormuz, when will the war end?
Before using Musk's "Western WeChat" X Chat, you need to understand these three questions
The X Chat will be available for download on the App Store this Friday. The media has already covered the feature list, including self-destructing messages, screenshot prevention, 481-person group chats, Grok integration, and registration without a phone number, positioning it as the "Western WeChat." However, there are three questions that have hardly been addressed in any reports.
There is a sentence on X's official help page that is still hanging there: "If malicious insiders or X itself cause encrypted conversations to be exposed through legal processes, both the sender and receiver will be completely unaware."
No. The difference lies in where the keys are stored.
In Signal's end-to-end encryption, the keys never leave your device. X, the court, or any external party does not hold your keys. Signal's servers have nothing to decrypt your messages; even if they were subpoenaed, they could only provide registration timestamps and last connection times, as evidenced by past subpoena records.
X Chat uses the Juicebox protocol. This solution divides the key into three parts, each stored on three servers operated by X. When recovering the key with a PIN code, the system retrieves these three shards from X's servers and recombines them. No matter how complex the PIN code is, X is the actual custodian of the key, not the user.
This is the technical background of the "help page sentence": because the key is on X's servers, X has the ability to respond to legal processes without the user's knowledge. Signal does not have this capability, not because of policy, but because it simply does not have the key.
The following illustration compares the security mechanisms of Signal, WhatsApp, Telegram, and X Chat along six dimensions. X Chat is the only one of the four where the platform holds the key and the only one without Forward Secrecy.
The significance of Forward Secrecy is that even if a key is compromised at a certain point in time, historical messages cannot be decrypted because each message has a unique key. Signal's Double Ratchet protocol automatically updates the key after each message, a mechanism lacking in X Chat.
After analyzing the X Chat architecture in June 2025, Johns Hopkins University cryptology professor Matthew Green commented, "If we judge XChat as an end-to-end encryption scheme, this seems like a pretty game-over type of vulnerability." He later added, "I would not trust this any more than I trust current unencrypted DMs."
From a September 2025 TechCrunch report to being live in April 2026, this architecture saw no changes.
In a February 9, 2026 tweet, Musk pledged to undergo rigorous security tests of X Chat before its launch on X Chat and to open source all the code.
As of the April 17 launch date, no independent third-party audit has been completed, there is no official code repository on GitHub, the App Store's privacy label reveals X Chat collects five or more categories of data including location, contact info, and search history, directly contradicting the marketing claim of "No Ads, No Trackers."
Not continuous monitoring, but a clear access point.
For every message on X Chat, users can long-press and select "Ask Grok." When this button is clicked, the message is delivered to Grok in plaintext, transitioning from encrypted to unencrypted at this stage.
This design is not a vulnerability but a feature. However, X Chat's privacy policy does not state whether this plaintext data will be used for Grok's model training or if Grok will store this conversation content. By actively clicking "Ask Grok," users are voluntarily removing the encryption protection of that message.
There is also a structural issue: How quickly will this button shift from an "optional feature" to a "default habit"? The higher the quality of Grok's replies, the more frequently users will rely on it, leading to an increase in the proportion of messages flowing out of encryption protection. The actual encryption strength of X Chat, in the long run, depends not only on the design of the Juicebox protocol but also on the frequency of user clicks on "Ask Grok."
X Chat's initial release only supports iOS, with the Android version simply stating "coming soon" without a timeline.
In the global smartphone market, Android holds about 73%, while iOS holds about 27% (IDC/Statista, 2025). Of WhatsApp's 3.14 billion monthly active users, 73% are on Android (according to Demand Sage). In India, WhatsApp covers 854 million users, with over 95% Android penetration. In Brazil, there are 148 million users, with 81% on Android, and in Indonesia, there are 112 million users, with 87% on Android.
WhatsApp's dominance in the global communication market is built on Android. Signal, with a monthly active user base of around 85 million, also relies mainly on privacy-conscious users in Android-dominant countries.
X Chat circumvented this battlefield, with two possible interpretations. One is technical debt; X Chat is built with Rust, and achieving cross-platform support is not easy, so prioritizing iOS may be an engineering constraint. The other is a strategic choice; with iOS holding a market share of nearly 55% in the U.S., X's core user base being in the U.S., prioritizing iOS means focusing on their core user base rather than engaging in direct competition with Android-dominated emerging markets and WhatsApp.
These two interpretations are not mutually exclusive, leading to the same result: X Chat's debut saw it willingly forfeit 73% of the global smartphone user base.
This matter has been described by some: X Chat, along with X Money and Grok, forms a trifecta creating a closed-loop data system parallel to the existing infrastructure, similar in concept to the WeChat ecosystem. This assessment is not new, but with X Chat's launch, it's worth revisiting the schematic.
X Chat generates communication metadata, including information on who is talking to whom, for how long, and how frequently. This data flows into X's identity system. Part of the message content goes through the Ask Grok feature and enters Grok's processing chain. Financial transactions are handled by X Money: external public testing was completed in March, opening to the public in April, enabling fiat peer-to-peer transfers via Visa Direct. A senior Fireblocks executive confirmed plans for cryptocurrency payments to go live by the end of the year, holding money transmitter licenses in over 40 U.S. states currently.
Every WeChat feature operates within China's regulatory framework. Musk's system operates within Western regulatory frameworks, but he also serves as the head of the Department of Government Efficiency (DOGE). This is not a WeChat replica; it is a reenactment of the same logic under different political conditions.
The difference is that WeChat has never explicitly claimed to be "end-to-end encrypted" on its main interface, whereas X Chat does. "End-to-end encryption" in user perception means that no one, not even the platform, can see your messages. X Chat's architectural design does not meet this user expectation, but it uses this term.
X Chat consolidates the three data lines of "who this person is, who they are talking to, and where their money comes from and goes to" in one company's hands.
The help page sentence has never been just technical instructions.